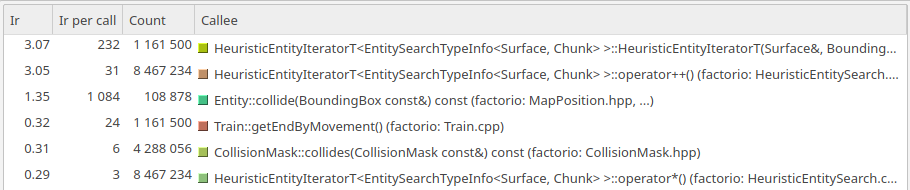
The profile data in the scenario with trains in front having a lower train id.
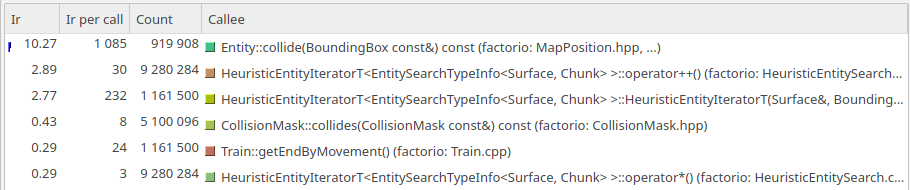
The profile data in the scenario with trains in back having a lower train id.
Yes, trains that are close to each other can have performance change depending on their update order.

Each train in the game has an id assigned to it. Such id can be read with the circuit network when a train is stopped at a station or by viewing entity info window. Each rolling stock has a train id, but multiple rolling stock combined into a train share one common train id. Additionally, there is an entity id for every entity in the game. It is not possible to read such a value, at least not one that I've found.[3] Connecting and disconnecting rolling stocks together updates the train id, but does not update the entity id.[1]
In an example tick, entities are updated with the lowest id being updated first (entities are updated on a per chunk basis which complicates this, I don't know how this affects it). This also happens for trains, lower train ids will be updated before higher train ids. Consider a hypothetical case where two trains are right next to each other, and moving. If the lower id train is in the back, it will do its calculations to determine on which tile it will be in the next tick. If it would hit the front train, it is forced to do many calculations. Next, the front train would be updated, moving it clear of the back train. It may then be required to update the back train once again, to determine where it will be.[2]
There are two properties we wish to test, the train update order, and the entity update order (within a train). It is theorised that the entity update order will not have signifigant effect since the things updated based on entity (rather than train), are not dependant on other entities in the save.
To test this, let's take out hypothetical case and make it reality. We will have 101 tracks, each with 23 trains (1 locomotive per train). We will assemble the trains such that the lowest id is either the train leading the pack, or trailing the pack (and all further trains having a higher id down the line). Trains will be spaced at the typical distance between rolling stock that a train typically has.
Additionally we will test if the entity update order (rather than the train update order) has any effect. To do this we make create locomotives in order from front to back/back to front. We keep the trains of 23 wagons merged into one train. Thus, there is 101 trains of length 23.
Finally we extend our tracks far into the distance such that no train will reach the end before our specified benchmark duration. This ensures we are only looking at a period where trains are constantly moving.
For funsies, we can also look at performance when the split trains have crashed into the end of the track, and perform a benchmark there. This provides a different view, where instead of collision checks never resulting in a collision, all collision checks are a collision.

First up, the entity id within a train does appear to be completely irrelevant.
Secondly, train id does appear to make a signifigant difference, but only when not crashed. Crashed appears to be effectively with the margin of error, and further successive runs could flip the result either direction.
The interesting result is the moving split configuration. Here, run to run variance cannot explain the roughly 7% performance gap. The gap is actually massive, when you consider how exceedingly similar the two test cases are. When we take a profile of each of these two maps, there is one immediate standout which takes a lot longer in one case than the other.
The profile data in the scenario with trains in front having a lower train id.
The profile data in the scenario with trains in back having a lower train id.
It is clear that collision checks are called way more often, but at roughly the same cost per call. It would appear that within a tick, a lower train id moves out of the way before the one behind it causes collision checks unnecessarily.
In practice, will such a design consideration matter? Probably not. This data does show us that small or insignifigant differences may not in actuality be small or insignifigant.